

Microservices, the future of society, and all that...
Modularity for introverts and extroverts ...or what it means that large things are an accumulation of small things...
21st October 2017, Based on Keynote for Reactive Summit 2017
This is an essay about how we draw boundaries around things, and what that means to us. It sounds like a trivial thing, but its quite the opposite. It's a subject that never ends in computer science. It extends from how we write code to how we run code, and how we apply code, how we make systems, how we view their results, on and on. Obviously it spans both Dev and Ops, the builders, the machines -- and even the users (heaven help us). And a key point is going to be how we distinguish things we draw boundaries around, which is where promise theory comes in.
I'll talk a little bit about some current technologies, in a while, but I want to start by looking at universal ideas.
(I) Boundaries and limits
Boundaries obsess us on any number of levels. In IT we talk a lot about `modularity', almost with an obsessive compulsion. There is a strict doctrine that modularity is truth and wisdom, and we have come up with all kinds of stories about efficiency, security, logical correctness, maintainability, reusability, and all kinds of other reasons why this dogma is correct. But, like all doctrine, we rarely question it very carefully. Politics are very black and white. Elsewhere in society, we put fences around buildings, gardens, plots and fields; speak of nations, sovereignty, and set up border controls around them.
From a business perspective: modularity is linked to reuse in mass production or commoditization only when modules are generic, where indistinguishable instances follow from use of a template. Think of data model normalization, or object classes. The more targeted we are, the less generic we are, and the less reusable we are. This is a basic law of information. To scale effort through reusability, we need to make things generic. Herein lies a paradox for microservices that I'll come back to.
Modules appear in systems everywhere: not just in human designed systems, but also in biology where evolved structures, like cells, organs, species, etc are used to contain adaptation to certain `contexts', e.g. stomachs for holding acid.
What I want to argue here is that boundaries are not only about protection and functionality, they are also about how we confront scale through trust, and the promises on which that is based (i.e. predictability and comprehension). This is a social issue, not a simple matter. Can we trust the whole, or only the parts? We can divide a system up, but what will its properties be when we try to put it back together? When can we coordinate parts explicitly, and when must we leave outcomes to be emergent?
The modular strategy has been reborn through microservices because of a greater need for rapid adaptation, and any adaptive system needs to be cognitive systems. Whose interests do we place first? When is cost of cooperation just too high? When does a company choose to buy or absorb its supplier rather than outsourcing to it?
This may all sound obvious! But we don't always get it right, because we are generally conflicted about the tradeoffs when adopting a particular strategy. We want to have our cake, eat it, and profit from it all at the same time. There is a deep on-going connection with knowledge representation taking place here too, because, once we have chosen a set of modules, (think of the static data models of the 1980-1990s) we might have locked a system into a particular viewpoint from which it is hard to escape, and the more modules we have the worse it gets.
Early cities had boundaries for protection, but soon benefitted from the close proximity this resulted in, on the inside, leading to mixing, innovation, and productivity.
Scaling with limitations
As a system grows in size and complexity, we think we want to know all the details, even though this quickly becomes impractical. We don't really trust our creations to behave according to expectations. But, this shouldn't be a surprise: we don't need to know about the behaviour of every cell in our bodies, but we continue to work approximately according to a lower level of expectations. IT suffers from detail sickness.
Key to these issues is a surprising remark: that scalable information management is about controlled forgetting. In statistical mechanics, this is part of what is known as coarse graining, and it's related to entropy. For this reason, we are also conflicted about boundaries. On the one hand, we want to separate concerns, but then we always need to unify and cluster back together in the next breath. So what is it about bounds and limits that makes them so important?
Of course, there are basically two things:
- physical separation - standalone, freedom to self-organize, discrimination of causation, or barriers to propagation of influence (information of many kinds) We give this up in order to work together.
- logical separation - autonomous, discrimination of intent, or interpretative labels We subordinate ourselves to a greater purpose on a larger scale. (Every system has new promises on each new scale - e.g. resistor, capacitor, radio.)
These refer to how we separate things in space, but we should not forget separation in time! Events, whether standalone or regular, localize information in time, and this is related to the ability of information to propagate from one agent to another.
Modules may obviate the need for dealing with certain issues: they allow the module to hand off issues to others in its network, but this also means that they are about shirking certain responsibilities, in payment for more concentrated specialization. This is good for a local agent, but possibly a problem for the system or society as a whole. It is a form of information channel separation, like clarifying signal from noise.
Boundaries or limitations are therefore as much cognitive aids as they are barriers to passage (modules are not failure domains, for instance, because we always connect them to other modules and therefore allow for fault propagation). Having separated these modules, the first thing we need to do is put them back together. Can we trust the whole or just the parts? What will be the properties of the recombined total?
Modularity doctrine
When the phrase microservices was first used, I was sceptical of the arguments. When I wrote CFEngine, as a single author with a culture of one, and then started a company, the professional developers all said: this is a catastrophe a hopelessly tangled piece of code! We must break this up into modules! Whereas I started out with two header files and a directory full of a hundred. When they were finished there were about 50 header files and three directories of a couple of hundred files. The code was just as tangled as before, but now you couldn't easily search for anything either, because you had to know, not only the names, but also where to add or look for all the functions---not to mention include maybe 20 header files instead of just one. There was a new level of complexity added, not removed. This combined with all the API hoops one has to jump through to instantiate objects made the code harder to understand, even as it removed some limitations from the original.
Was this easier to maintain? The argument goes that, with modules, one can work on just one part at a time (ignoring the side-effects on other parts). But in fact you can't always do this if the nature of the application means that the parts are meant to be closely dependent on one another (some things just are complicated).
Modularity is a way of divesting oneself of responsibility for change. Micro-modularity makes it apparently, locally, cheap to delete and replace promises or their implementation, and without considering the impact of the change downstream. This makes change someone else's problem.
Recall the crash of the Mars probe, some years ago, which was a result of non-calibrated promises between different teams, concerning metric versus imperial measurement units.
This horrific personal trauma has no doubt marked me for life, and led me to break into a sweat at the mention of modularity, but this is not just a joke. One can actually count the complexity of code in objective sums and show that the modular code has more pieces, and is therefore more complex. The cost of collaboration is always positive. More interestingly, it is also possible for the benefits to outweigh the costs in some cases, as we observe in the economics of cities. I'll come back to that later.
Where are the good languages that make these include file issues simpler, instead of pushing the burden onto programmers? If programming system is a service to programmers, then all this violates the tenet of a single point of service (ITIL). A single point of service is a meeting place for users in the human realm, a shared identity.
Human-computer promises
Scaling of system promises is not a one dimensional issue. We started to think differently about scaling when DevOps and especially Continuous Delivery (a la Humble and Farley) got highlighted. They emphasized that systems are human-computer cyborgs, not just lumps of deployed code---that software is always delivered as a service, on some timescale or other, and that this cognitive loop is central to software stability.
Continuous delivery therefore highlights that software is a kind of learning process, a cognitive loop of self-healing adaptation, exactly like the one I had build for system maintenance in CFEngine. There is a literal sense in which the code learns, indirectly through the reaction of developers to bugs and production experience, as well as the programmers themselves. Indeed, the learning of the code is more important than the learning of the developers, because developers may come and go, but the code may remain in its environment for much longer.
It makes little sense to separate the maintenance process of any manufactured item from the manufacturing of the item itself, if it needs regular maintenance on the same timescale as its operation. A ten year overhaul is one thing, but endless patching is a different story altogether. It is about the stability of a system in keeping certain promises to its users.
Promise theory is a way of combining two different complementary aspects of systems: dynamics and semantics. How they behave, and what is their intent. The scaling of agent architectures can be understood by promise theory. It doesn't much ,matter whether the agents are humans or machines. It's about the promises not their vessel.
What agents express is locality, atomicity---the building blocks of modularity. Locality brings maximum predictability. Modularity allows us to limit the information fed to other agents, especially humans who have very specific cognitive limitations.
Basic Promise Theory (a chemistry of intent)
Promise theory takes the view that autonomy, or standalone behaviour, is the default state for any agent, provided it has sufficient independent resources to keep its promises. This is a kind of atomic theory, analogous to chemistry for intentional behaviour. Agents can voluntarily rescind that autonomy in order to collaborate and coordinate with others. Trying to impose on other agents, to induce them to cooperate, is not disallowed but is generally ineffective. Promises allow for a pluralism of intent, whether by design or by accident. This may be the opposite of what one needs for trust or efficiency, but it captures the diversities that accompanies many degrees of freedom (not all of which we control).
Promise theory divides the world up into agents, promises, impositions
and assessments. Its not so much about the agents as the promises they
make and hopefully keep.

A simple way to comprehend the effect of influence is try to break a system down into atomic agents, each of which makes promises independently, and then to try to put these elementary agents and promises back together to reconstruct the full system, with everything that entails. In this way we require a complete documentation of promises, and nothing can be taken for granted. It is very easy to talk about in-sourcing and outsourcing in this way.
Scale plays a role here. Agents can work together in `superagent clusters', and each aggregate superagent can also make promises. Thus new collective promises may appear at each scale of aggregation.
Superagent fragilistic expialidocious
A superagent doesn't need a physical boundary. but it can be drawn as if a logical set boundary (a Venn diagram) encircles the members of the set. Agents only need to share common promises or act collectively to form a superagent.
The boundary of a superagent, i.e. its modularity is a
labelling of the agents within it, which is orthogonal to any
collective promises the module makes, and may indicates new structural
information. In order to coordinate the same membership of all, one needs
a central calibrator O(N) or an expensive peer consensus O(N2).
The labelling is worth it when the scale of the implies boundary matches the
scale of interaction of the collective.
The boundary may be opaque or transparent. We offload to the exterior.

Borders are therefore about the trust in approximation, and tagging ownership of that approximation. A labelled (card carrying) member of a superagent set can be trusted to keep the promises necessary to keep the promise of the whole superagent, without subjecting it to a detailed assessment. A superagent does not have to expose all the details of its interior, and therefore it can be discussed as an entity -- a data-compressed representation that exposes only exterior collective promises.
This loss of detail is part of a generic property of weak coupling, which is the increase of entropy, i.e. forgetting of detailed information. It is really fundamental to the stability of systems. If we need full information about everything to understand the behaviour, errors and faults in interior promises can propagate upwards and spread. We might want to look inside to debug superagents, but their main promisees should not need to.
In practice, the aggregation of agents into superagents is about labelling intent (for mental hygiene, separating signal from noise) more than it is about security or isolation; because, while we recognize the importance of autonomy or locality for predictability, cooperation has already compromised that aspect of the modularity. I want to argue that boundaries are about managing predictability cost effectively.
H2H, H2M, M2M
So a key point to emphasize about promise theory is that the type of agent, whether human, animal, mineral, or machine, is not that important, only its ability to keep certain promises. This is because we make promises out of trusted invariants.
The same ideas of scale and information apply to any working system, of course, even one that doesn't contain machines, because the very essence of human industrial organization is to suppress our humanity and try to behave in a mechanical way - based on algorithms. As machines, humans don't always reproduce behaviours with the kind of perfect fidelity we would like for quality assurance, but this is why we always have to remember that any machine (of any technology) will only keep its promises part of the time.
Systems exist for a purpose in the following sense. Either they were designed to keep some kind of promise (+). or they were evolved to fill a niche need, fashioning themselves on a promise to accept (-). They emerge or are created with a functional intent, i.e. a promise, and therefore we have to understand that and measure them by that measuring stick.
This is what promises are for. We state our intentions (like the Borg) and then we can be assessed for compliance. There are two kinds of assessment, that we can call either
- Quantitative - dynamic, compare to standard amount, time, etc (mainly OPS)
- Qualitative - semantic, compare to standard meaning ... (mainly DEV)
(II) Applying promises
Now, let's use these ideas to examine the architectures, bearing in mind that our simple drawings don't necessarily capture every promise the agents make.
The good old fashioned (standalone) monolith
Consider our cartoon version of a monolith, as a kind of castle under siege. We like to make fun of the monolith as a kind if bastion of antiquity. Inside is a tangled mess of curdled interaction. I'm sure this picture below is familiar to everyone from your old castle siege days. It explains several limitations we have in understanding and coping with scale, and about modularity. There is the single modular castle facing up a sea of attackers, so large in number that they appear to the castle as a continuum.


The structure is of a collection of modules. P is a programmer agent (like the castle leaders), M is module (an archer on the castle wall), T/O is a test/observation agent that assesses the promises made by the modules. This includes the infrastructure on which the intended code runs (which makes its own assessment of the code). U is the end user (or invading force). Hopefully the promises made to the testers are the same as the promises made to the end users, though we know this is not entirely true, e.g. unit tests.
Notice that the separation into superagents based on these roles leads to a separation of responsibilities rather than a separation of concerns. The code M sits like a router or switch between a number independent cognitive relationships: it adapts to the needs of developers, tests, infrastructure, and users. Why then do we think of the system only as the code, and not these other vital sensory inputs?
This prompts more questions. Are these the appropriate boundaries? The promises made to the end users might be conditional on the tests:
function | test passed M --------------------------> U
Who or what is driving the workload on the M? Is it the users (events) or is it the developers (determinism). Does this matter to the architecture? Are the promises kept synchronously (as impositions) or asynchronously (as voluntary cooperation promises)? Indeed, it might matter to the ability of the network to cope with the aggregate load, but this is more a question of how we share load.
Can we just change the nature of the connections and call it microservices? After all, if we've done our layer abstractions right, it shouldn't matter what the transport agent is -- Ethernet or PCI bus.
The castle against a sea of arrows (detailed balance)
In some industries, like aerospace and shipbuilding, we build small scaled models that can be related by dimensional analysis to their full size production examples. But in IT, `scaling' simply means throwing more brute force resources at the problem: scaling by handling every exterior transaction through `detailed balance'.
How we perceive and model the workload matters. Because the attacking workload is composed of entities that we have a habitual relationship with, we find it hard to comprehend a collective bulk mass composed of them. There is a simple quantitative story, but cognitive limitations prevent us from seeing it.
From a distance, the castle appears as a monolith to the attackers. From the same distance, the attackers seem like a monolithic blob, a swarm or continuous sea of bodies. Only as they get close enough to see the whites in each others' eyes do they perceive another scale: the scale of detailed balance.
IT folks understand that, on the workload scale, we can meet this army one by one, arrow by arrow, as a detailed balance. That's how we serialize work in IT, as a parallel queuing problem for each archer in the castle. If the archers are independent, they can being autonomous, the workload can be `non blocking', so no one need to wait for the commander's instructions (or destructions). If they need to work together, some additional cost of coordination may slow them down.
If we look at the entirety, in low resolution, due to cognitive limitations, the attack has the apparent illusion of being liquid in nature--- a sea of bodies (our bodies are basically water), and this suggests fighting liquid with liquid, and we might try meeting liquid with liquid, by pouring oil, or firing large rocks.
Depending on how we draw the boundaries, then, a software system may appear monolithic because we choose to ignore several parts of it. The assumption that only the code matters (because the code is the perceived desired end state of the programmers, and the desired starting state of the users) makes a straw man monolith of the system. But we can't break the full end-to-end experience of the system into different modules. They are all entwined in a bloody interaction!
Load balancers or dispatchers...funnelling into monolithicity
Let's make a brief diversion to discuss scaling by imposition. If we don't want to confront scale, we may try to push it away. Suppose we set up a checkpoint in the field to organize the conflict.
Historically, we just put a load balancer in front of the battle to scale it, to share the load between several castles, or several queues. So, place your favourite manager out in the field to poll the incoming, "Uhm excuse me, would the orcs mind going to the other castle please. We don't have time for you today - you'll have a better fight experience!" Or: "You chaps take the assault ladder on the left, and you others on the right!"
In this view, no matter how modular the back end, it's the network funnel that ultimately shapes the monolithic aspect of a system at a given scale. But returning to the mass-production point in the introduction, we treat the back end as being composed to parallel modules that are all approximately identical. They form a high entropy mass, making them semantically monolithic.
The conventional argument of the load balancer is that redundancy
solves both load sharing and fragility in one fell swoop.
Does this redundancy really solve fragility?
The picture below shows how redundancy and horizontal scaling by
imposition forces parallelism all the way back to client itself who
initiated the service request. Promise theory tells us that it is
always the client's responsibility to get service, not the provider's.
So push based systems with high load are an example of how
impositional thinking gets you into trouble.

The image below shows how we really scale horizontally:

This is the approach used by Content Delivery Networks, using DNS as a very primitive but effective technology for scale-management or load sharing. Provided agents are not hostile, rather than funnelling all traffic into a single queue, a simple informative promise to provide traffic information to clients can successfully load balance. A brokering of clients and servers is used in CDN, Corba, and other systems. It introduces an superagency that works at the same scale as the scale problem itself, rather than trying to funnel a macroscopic problem into a microscopic middlebox.
Scaling impositionsThinking in promises is not natural to us: we are manual egocentric creatures and we are used to controlling our limbs by imposition. Imposition does happen, but it is either illusory or a form of attack.
You push the electrical signal onto the wire, and you have to deal with collisions, or you promise to follow clock pulses, after that everything is a pull. The receiver interface pulls from the wire, the kernel pulls from the interface into a queue, and the application pulls from the queue into its socket. It looks like a push, at a high level, as long as the promises exist on the receiver end to to maintain that illusion.
- Scaling imposition is expensive - if you want something you'll keep trying, because there is no such thing as a guarantee
- Scaling asynchronous promises is cheaper - in favour of reactive manifesto
- Avoiding middle management is most efficient
- Figuring out what promises to expose and which to hide, at which scale
One benefit of changing the scale of integration is to be able to get into the inside of systems in an ideal world, if we engineered things well, we would not need to do this. It leads to strong coupling. But we are not that good at understanding systems, so we still need to debug interior promises. By using the same network for everything, we can remote debug more easily, and alter the architecture at runtime, without total recompilation.
Can we really scale promises? (the pejorative monolith)
Can we keep the same promises as we scale a system, or must the system change qualitatively and quantitatively into something else? This has implications for technology and for human societies, from companies to nations.

The point of the previous section was that monolithicity is a figment of scale. The monolith represents the approximate invariant characteristics of a large mass of stuff, not its detailed behaviour. At the level of cells, a brain is complex spaghetti of neurons; at the level of a person it is lump of sponge. At the level of a city, Hong Kong is a tangled spaghetti of interaction, but at the level of an island it is a blob of land. The mess that is a dense network is efficient and rich in properties and innovation. We can choose not to see the mess, but it still exists.
The depth versus breadth problem says that a system may have intrinsic complexity. We can reduce the depth of recursion in a problem by introducing more modules, but the coordination between them has to grow in order to compensate. Since coordination grows up to O(N2) this might be expensive. Only horizontal breadth without distinguishability (high entropy) has be scaled at low cost.
The challenge to invariance is from rapidly changing environment. The main question we have to ask ourselves is therefore: are we looking inwards or outwards? And with respect to which arbitrary boundary?
Is a city a monolith or a network? Is a brain a central monolith or distributed network? This question is meaningless without a scale. While some dynamical processes can be made scale-free, semantics pin a scale, because they relate to specific named agents.
I recall that the MBAs in my old startup would cry "focus focus focus" is the only way we can scale the business. But this assumes a constant exterior environment: opportunity is rarely monolithic, and by definition irregular, so focusing on one thing will not guarantee more success pon a monolithic strategy. Opportunities are more microservices than monoliths. The days of singular global commodities are over for most businesses.
A microservice phase transition
Focusing on the wrong challenge may result in a monolithic design, with respect to exterior adaptation. If we redraw the various agents in a different configuration, like a phase transition of the first, we can redraw the lines of cognition to enter the battlefield of interaction at the level of detailed balance. This is appropriate for enacting change at the level of system details, but it may not represent all interests equally well. See the figure below.

In this new rendition of the interactions, the outer boundary seems more porous, less of an intended barrier, in order to promote a direct explicit causal relationship between modules and people. The boundary is now `fractal' and reaches into the system at the scale of our choice. The modules are the same, but their timelike cognitive interactions have been reorganized and refocused. The technologies underlying the connections are not really represented here. Whether modules link by PCI bus or by Ethernet connections is not of primary importance.
If one draws the architectures of microservices, from a purely IT perspective, they look basically the same, mapping the promises one-to-one. But the details of the promises may be different. If you replace the wings of a plane with polystyrene, it might work on your scale test model, but not in production. It might not support the scaled narrative. Once we focus on the human cognitive relationships in the picture, we can see a different narrative structure, one that scales in detailed balance, rather than as a bulk offering. The cognitive interactions are more localized between dev and ops. Consumers may or may not interact differently with the entire system and its narrative. They may or may not notice a difference in the operation of the system.
Thus the way we can understand microservice architectures in promise theory is as a reorganization (a kind of phase transition) of the promise-keeping and its essential timescales. The modularity argument supports mainly developer convenience, particularly related to the speed of repair (which is for user convenience). But a microservice collaborative argument is more than that. It is a complete reorganization of the interaction timelines.
When do we build the relationships? If we put a monolith together first and then try to build the relationships to the external parties, the cost of building is low, but the cost of adaptation is shifted to the maintenance phase. In a microservice approach, the cost of forming those cognitive relationships is shifted from post-release to pre-release. We'd expect it to take longer to build the first version, but later versions could be faster at adapting to change, provided of course the nature of the modular relationships doesn't change.
Microservice thinking is a re-optimization around the humans in the human-computer system. This seems like progress on one front, but not necessarily on all. As a human-machine optimization, tied to a number of cognitive relationships, the continuous delivery model of production is one for semantic stability. Given the poor record software has for reliability, and its increasingly mission critical role in society, the need for realtime agility is a major reason for emphasizing any aspects that can shorten the continuous delivery timescale. It's no longer a question of `time to market' for the product offering, but `time to stability'.
One argument for the rise of microservices, as REST-API services running on top of the web, could be that it is simply a technology preference or a generation that has grown up on these norms. Like most successes, it builds on the popularity of a cultural adoption. Another is that the efficiency of this cognitive software learning process becomes the new main object or focus for optimization, once developers are liberated from operational concerns by the assumption that the cloud is both cheaper and has infinite capacity. The cheapness is already in question, but the capacity remains more or less true for most intents and purposes.
Channel separation (the Dunbar limits)
Psychologist Robin Dunbar taught us that fixed cognitive capacity in brains implies that the more detail we focus on the fewer things we can accommodate, because the time to learn familiarity is longer. Interestingly, our human cognitive limitations can be partly transferred to and replaced by machine cognitive processes, e.g. in continuous delivery or in machine learning, which I'll return to below. It is this cognitive aspect of the system that we are optimizing, because we know that the sensor experience of the microservices is rechannelled from both users and developers into a continuous delivery learning process, memorized through code changes.
The reorganization is a channel separation of the information from human-facing sensors, including developers and users. The information in code modules must be the same, in both monolith and service arrangements, if they do the same job, but now we have a new risk: because the modules interact with one another, and depend on one another, a change in one can cause a fault in another. If exterior change only affects one `agile' module (like a smaller monolith) we might create uncoordinated changes that lead to promises being broken between the modules. And because there is a greater overhead and more dependency with greater modular separation, there is also a real chance of systemic failures being more far reaching.
One way around this is to separate clearly the promises that the modules make, and redraw the picture more carefully. With respect to some promises, the modules are separate, but with respect to others (so-called dependencies or cross cutting concerns) they are a single monolithic blob with a shared commons. This promise viewpoint can explain aspect oriented programming and object oriented programming in terms of promises.
Hidden dependencies shatter the illusion of independence
We should now be able to see that modules are not failure domains. Propagation of faults depends on the promises made, not on the size or number of the modules. If we use modules as containers for processes that might be locally acceptable, but globally toxic, e.g. containing acid in the stomach, we should be aware that there can be acid reflux and ulceration by hidden channels.
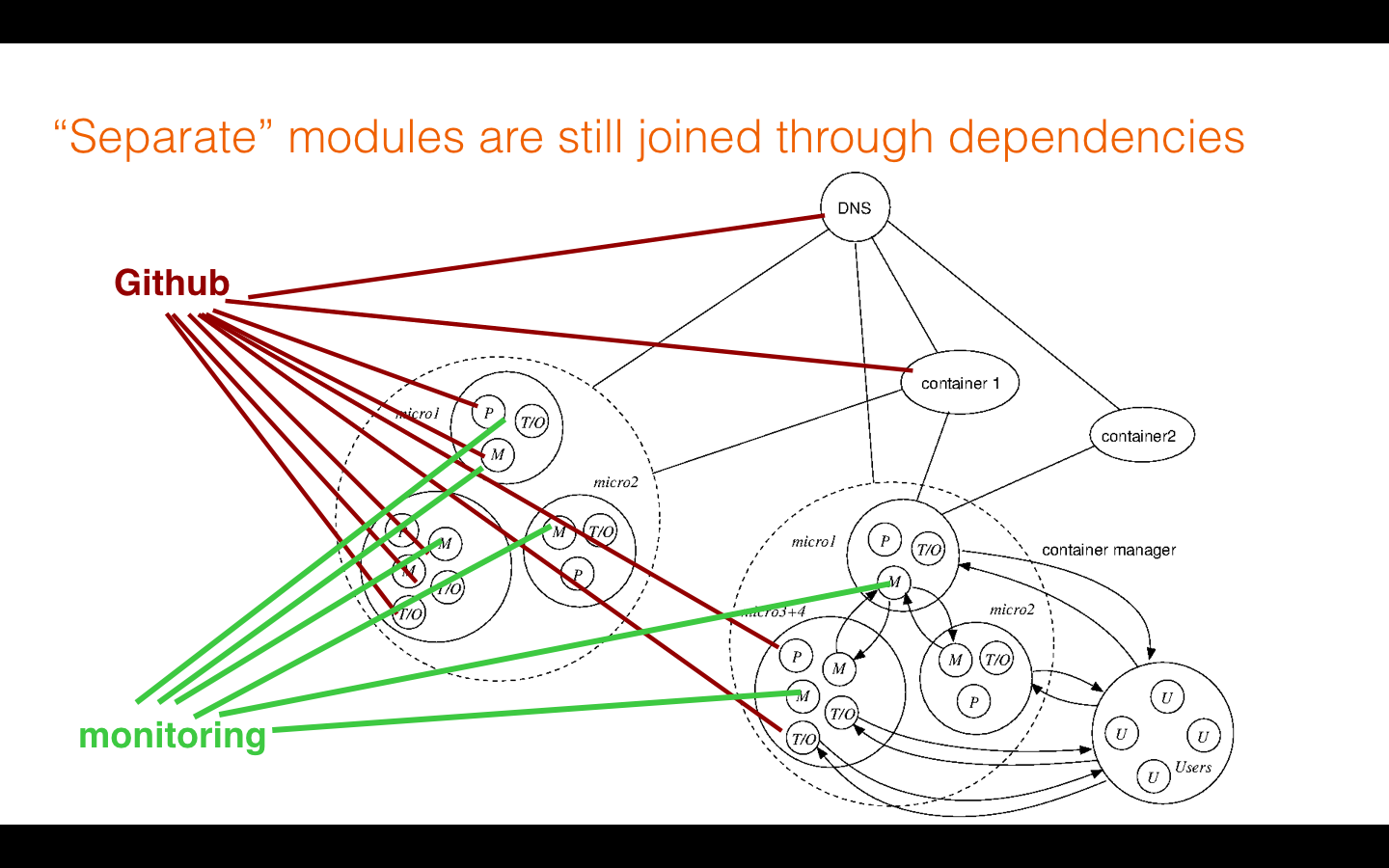
This final picture shows that we should not be too trusting of these modules as strict failure domains, because there can still be propagation of faults through these third party `covalent bonds'---the most important of which is the sharing platforms they all run on: kernel and cloud.
When A depends on B and C depends on B, A and C may influence one another through B. Influence has a limited transitivity, through promises, depending on the nature of the promises between them. This is a pretty complicated issue that I deal with in my treatise project.
Recall the node.js scandal of micro-packaging, where a single package to strip whitespace was withdrawn, breaking thousands of other packages: the interior structure of a module matters too. Dependency became a major liability.
(III) The meaning of scale
From promise theory, we know that there are two aspects to consider about systems: quantitative and qualitative aspects of systems together (making the world's smallest passenger plane, or the world's largest microchip are probably inconsistent goals). These two aspects influence one another through shared dependencies (especially platform `commons' dependencies) and scaling one may be straightforward but may also sabotage the other. So, we need to ask if a system can continue to keep all our promises (to various stakeholders) as a system scales?
In IT our idea of scaling is basically modelled on industrial productivity: how can we throw more resources at a deployment to cope with more demand? But this is just too naive, and we need to think more deeply.
In physics, scaling is about the more subtle question: what things remain invariant about a system when we rescale it or parts of it? This is a powerful question that is right at the heart of the matter of how autonomous or interdependent things can be. To discover what is invariant, we have to be able to discriminate signal from noise in information, because signal is by definition that which has invariant meaning, and noise is everything else. This is a cognitive learning problem. Our perception of promised characteristics is a subjective assessment: can we promise to separate colour from sound, speed from size, and so on. Invariance is the key to an ability to recognize and modularize separable observables, because we are really asking how can we preserve certain promises within a certain scope.
We all have some idea about dynamical quantitative scaling: double the size of something, might lead to double the work, or four times the work. Algorithmic complexity theory measures the amount of work in a serial Turing process as O(N), O(log N), O(N^2) etc, etc.
Semantic scaling is more subtle though. What is twice the functionality, or half the functionality? Think of menus. We have to use sets to describe function. So it is easier to say does the set of functions change as we alter a system by increasing or decreasing something.Sharing the risk/burden of bin-packing aggregation across multiple users.
- If we double the number of servers, what happens?
- If we double the number of lines of code, what happens? (Numbers don't help, but promises do)
Aggregation with approximation enables cheaper scaling...
An important lesson is emerging in the foregoing argument. We can draw boundaries differently in a system to support different issues, but the complexity of the boundary can play a major role in the scaling behaviour of the system. Modularity is mainly useful for scaling if it is accompanied by entropy. i.e. if the details of what goes on inside are forgotten when we zoom out. An army of equivalent redundant soldiers is easy to manage, but an army of individuals carries a quadratic cost of coordination. If we can lump things together under a simpler label, we can commoditize them and achieve economies of scale by treating them all the same.
The scales of vertical and horizontal change are important. A sufficiently large asteroid (or boiling oil) can take out your entire system in one go, regardless of how many redundant servers you have in your datacentre. The scale of redundancy relative to the scale of a failure is the relevant dimensionless variable we have to consider. The rate of component repair relative to the rate of component failure is the vertical scaling dimensionless variable we have to consider.
Semantic scaling means zooming out, and treating interior promise networks as black boxes. If we do this, we can make the boxes functionally indistinguishable the share generic resources, like a utility. If we make everything too specific, too precious, semantics can quickly become overconstrained and networking will collapse into separatism, with a high coordination cost.

Dynamically, under-utilized systems may exhibit economies of scale by centralization of provided the parts are relatively independent. If there is dense interaction, up to O(N2), this may become suboptimal (Gunther's coherence argument). This effect scales too. It has been studied in much greater detail for another kind of functional scaled arrangement: cities. Studies initiated by the Santa Fe Institute show how successful informational networks do survive scaling by sharing basic communication infrastructure within a non-saturated regime of service utilization.
So breaking up resources and reconnecting them might be wasteful, especially if additional overhead is added. When services share common resources they can save duplication costs by consolidating (up to the point it could be a bottleneck). This could lead to a single point of failure. But if costs grow faster than linearly, this could choke the system and limit its growth.
Resilience suggests the opposite. Resilience has a cost, but a cloud platform can minimize that by offering generic shared services across different promises or services, so that several workloads share the same risks, all with redundancy. The catch is that they need to be generic workloads.
Vertical and horizontal scaling -- are illusions of scale
Adrian Cockcroft pointed out once that a fast response (MTTR) was more effective than a redundant failover, in his work at Netflix. He used this as an argument for microservices: a close connection between human and code and infrastructure, thus optimizing the human-machine interaction loop. It's easy to see why this is a provably true statement. Failover and redundancy require cooperative promises that link modules together in various interdependent ways. Horizontal scale can be transduced into vertical scale by speed, where one could trade the need for extra underutilized failover resources for a bottleneck. Redundancy can also create inertia (in good and bad ways), baggage to carry around, and the modularity barriers become a hindrance rather than a help to access.
Actually vertical scaling is preferable for low overhead cost and first line resilience, but it is ultimately a single point for complete failure (e.g. to a large dinosaur-killing asteroid). Self repair is functionally superior to redundancy, if you can arrange it. Nyquist's law tells us the sampling rate a system needs to have to self-repair fast enough so that can't even observe whether an error occurred. All our memory chips exploit this every second.
Rescaling the cost of modularity
Are we looking to the inside or the outside? Interior structure may contain all the same problems as the exterior structure.
On the interior of a boundary, inside the black box, subsystems may interact in any number of ways. Economies of scale are complicated. They change as the circumstances and technologies for aggregation change or evolve. The garden city movement postulated that cities could be designed to be beautiful and efficient by modularizing: residential, business, shopping, etc. But the result was a disaster: the tidy arrangement simply left the residents stuck in traffic, all trying to move from one to the other at the same time. The spacetime coherence in movements (all citizens working and shopping at the same times) led to continuous bottlenecks. Breaking these monolithic service points up into a messy Chinatown is much more efficient, but perhaps less aesthetically appealing.
In the early days of the telephone, we used to have to go to the post office to make a phone call. Then we deployed shared phone boxes. Then everyone had a phone in their homes. Now, the costs are such that everyone can have their own distributed phone in their pockets. The monolithic aspects of the system have been rescaled, as the boundary of the service has been made finer grained, and only the resource-sharing infrastructure platform is monolithic.
The monolithic control of our infrastructure platforms leads to calibration and standardization of expectations, but also throttles, bottlenecks, and common failure modes. Direct peer to peer networking over a wide area would not scale efficiently for continuous use. We know from the city studies that infrastructure needs to be kept cheap.
Scaling technology so that everyone gets their own washing machine, fridge, phone, brings individual agility: autonomy that isolates us. Agents no longer need each other at the local level. Central services offer scaling efficiencies are driving a wedge in society (slogans). The ability to get everything, to 3D print anything in the future may lead to a reversal of globalization, disintegration of mutual understanding and coherence, and a re-emergence of global conflicts. This view is supported by Joseph Tainter's: The Collapse of Complex Societies.

We are taught, in school that hierarchies have a unique strict
order, i.e. a kind of golden ontology. This has led us to build
static data models and monolithic top-down software. But, a promise theory
view tells us that there is no unique hierarchical ordering of
entities, as we pretend in static data modelling. The figure shows how
complicated dependencies may even be circular across different
contexts.

The simple tree-like decompositions we prefer in computing are only spanning trees of a more general conceptual graph. By creating a more flexible boundary around a software system, we can take advantage of contextual adaptations that would have invalidated a rigid model.
Different kinds of promises may suit different kinds of boundaries, e.g. companies may not fit comfortably inside superordinate national boundaries, and their legal systems. We see this tension between imposed boundaries and innovation in a growing separatism around the world, e.g. Brexit, Catalonia, Scotland, Ireland, Hong Kong, etc. Companies use modularity for protecting intellectual property and other assets, using shell companies for instance. They also use subsidiaries are brand containers, offering convenience of cognitive separation.
Cooperative promises - from load sharing to innovation
Components can certainly be manufactured and tested separately, in order to focus on expertise, but they are ultimately useless unless they can be combined into products and services.
So what if we shift our thinking away from boundaries, for a moment, to focus on the complementary benefits of cooperation across those boundaries --- by the flow of information for the binding teams and clusters, for redundancy, robustness, and even networking for innovation.
Aggregating promises might have two apparently contrary purposes:
- (Experiment) To recombine differences together to form new difference (innovation) if we only mix a little, or
- (Industrialize) To commoditize by eliminating differences from the set, and relabelling all members with the same average label (leading to entropy or equilibration). This creates a new kind of monolith, however small.
The popular management belief in the superiority of teams always annoyed me, because (as a pathologically antisocial misanthropic introvert) I loathe working with other people, and I prefer to innovate on my own, rather than spending precious time in someone else's microservice party, in front of a whiteboard. I have already accumulated a lot of information on the interior of my superagent boundary (in memory) by exploring, reading, and talking---and in a style and tempo of my own choosing. It is debatable how efficient the imposition of random talking can be, compared to a scheduled and systematic search based on promised knowledge.
Extroverts might gain some emotional boost, or sense of inclusiveness and joint ownership, from these whiteboard fests, but (as a pathologically antisocial misanthropic introvert) I have the opposite response, and there is usually some clash of Myers-Briggs types that only leads to mutual irritation. This naturally horrifies all those extrovert MBA types who want to take ownership of that innovation, on behalf of teams, and then draw their own boundary around the intellectual property which happens to intersect with their bank account. Of course, ultimately there might need to be a coherence to the behaviours of the team members, but isn't that curiously already in question by opting for a more autonomous decomposition of modules? What, then, is really the point of autonomy and cooperation within these boundaries?
Separation into hierarchical scales has been accompanied by a rigid top-down causal narrative, implying a monolithic holistic approach to adaptation and opportunity. Running systems are constantly exposed to users, and developing systems (however immutable their stacks) are porous to change by developers, explaining why there are always many episodes of insider sabotage in security breaches.
We should not feign fear of these interactions, but rather learn what it means to stabilize them. If services didn't experience anything anomalous (in state or code) during their cognitive parlays, neither they (by proxy) nor we would learn, change or innovate. Unless systems were totally independent threads, with no sharing of platform, or common users (nothing at all), then separate services they would always share weakly coupled influence from outside and so they will gradually be attracted into similar states, through the same evolutionary pressures.
This is how cities adapt and evolve. Cities are like computer programs that are much bigger and longer lived. Cities have grown prosperous by keeping sufficient diversity within a densely local interior of some defensive barrier, where communication was fortuitously easy, thanks to the goal of defending against attack. Cities will serve as a model for the future of software.
(IV) Control by approximation: easing the cognitive burden
How can we apply these scaling lessons to the human realm, to grant necessary access, provide helpful containment, and to manage our limitations?
Cognition plays a hidden role in everything we do systemically. And singular (monolithic) symbols are are key to our very notion of comprehension and meaning. We routinely use stereotypes and symbols to compress data and avoid thinking about detail, replacing clusters of micropromises with a single monolithic approximation. Moreover, we trust stereotypical approximations more than `too much information'. We are more likely to trust something we have no hope of seeing into or understanding than something we can observe more closely. It seems that the more information we have, the greater our obsession with doubting and conspiracy. Today we are regularly exposed to information about corrupt and self-serving networks of privilege. Studies indicate that trust in the institutions of civilization may be an all time low today. This is surely related to our knowing far more about them than in the past. This monolithic representations serve an important purpose in shielding us from temptations to engage and form relationships with things we have not the cognitive capacity to entertain.
A cognitive system is one that observes, measures, and learns before reacting to what it observes. That already assumes the existence of a boundary: inside versus outside. Me and not me. Inside contains a unique memory that leads to a running context. Outside the experiences are beyond its control.
We struggle to reconcile such different views and perspectives, and contexts. When we possess little information or context everything seems simple, but when we know too much matters seem complex. That's why evolution has granted us the ability to forget. Forgetting is a key cost saving strategy.
Monoliths are irreducible symbolic entities. Western alphabets are like `microservices', in which each symbol is a small monolith. With few strokes of the pen, they are easily erased and replaced, and combined to form many different words. But they don't convey any meaning out of context. We have to write longer sentences. Their reusability, based on a phonetic model, is well adapted to generic sharing. Perhaps this is why our Latin modern alphabets are simplified from the more beautiful but intricate monolithic calligraphy of the orient.
Boundaries are helpful to offload unnecessary cognitive capacity consumed by detail, and also serve as a warning signal to help us to notice when we are about to do something stupid, like step off the edge of a building. Data types in computer science play a similar role. They are just membership cards to particular clubs, like "the totally get down real numbers", or the "existentially complex numbers".
Modularity may have more to do with mental hygiene than actual protection, since anything that is voluntarily undertaken can be undone, unlike (say) protection rings and kernel architectures, or "secure enclaves" where processes are forced to go through intermediaries that filter them independently.
Brands: signal from noise with maximum data compression
Modules are signposts to humans, as marketeers know well. These compressed representations of complex ideas help us to recognize and classify function. Ministry of X, department of Y. Clothes shop, food shop. Brand X, etc. Brands or functional identity serve as proper names for arbitrary clusters of services. Semantic distinctions guide us as to how we should behave towards them, and also how to make our machinery that enacts our desired behaviour by proxy.
The `micro' in microservices implies that a module is cheap to eject or replace. Don't invest too much, so that you can replace it without the sense of getting `locked in'. Of course, this is a bit naive. It's not code that is hard to replace, but its hidden assumptions that lock us in, e.g. reliance on load balancers.
Human scaling - Dunbar again
Humans form individuals, teams, companies, markets, etc. Human cognition is limited, and this affects our ability to trust. Our ability to scale into clusters depends on the intimacy of our relationship. Entropy plays a role. More detail, fewer friends.
The same applies to knowledge, because our capacity to know concepts is the same as our capacity to know friends or enemies. Promises are a great way to model knowledge - because knowledge is another issue that is about relationships and trust. As number of parts increase, our ability to know, understand and therefore trust a system decreases rapidly.
Knowing is not just about possessing information; it is about revisiting and trusting the same information over time. Knowledge is not ephemeral changing context but invariant certainty. This is why promises are related to knowledge -- we deal with what is persistent and dependable.
The meaning we attach to scale flips between high and low level interests, as we seek or set aside information in search of relevance.
| Unique, specific, low entropy | Faceless, generic, high entropy |
| Instance | Invariant class/type |
| Verification | Trust |
| One in a million | Safety in numbers |
| Visionary | Team player |
| Explorer | Patriot |
| Bespoke | Commodity |
| Credit | Cash |
Bounding cognitive simplicity for human-computer systems - "Workspaces"
Scaling tells us that we have to think carefully about who and what to optimize
for when making and keeping promises. There are semantic and dynamical concerns.
There is a
conflict of interest. The cognitive nature of an interaction serves as a
clue for choosing. The survival of the system, in remaining relevant,
depends on its ability to adapt.

If we try to handle diversity and myriad components by brute force aggregation, in order to fit a static hierarchical information model, we are likely to end up with a process that is fragile and prone to sudden failure. This is not an argument for or against microservices per se, but a suggestion that local clustering is better suited to modelling concepts in a stable manner than a rigid ontological hierarchy. The problem is trusting microservices only at a developer level is that whatever modularity these represent at a high level is often sabotaged by underlying infrastructure (think of the load-balancing issue).
Some years ago, I worked on a project with Herb Wildfeuer at Cisco, on this issue of handling the complexity of services in an Internet of Things (IoT). We came up with the notion of Workspaces, as a shrink-wrapped cluster of agents with a fractal boundary, working as a collaborative group, in a certain scope, e.g. heating in a smart building, traffic systems across a city, or bus scheduling, etc. If you are a physicist, workspaces are the semantic equivalent of coordinate patches on curved spaces: local regions of addressability that are adapted to a particular viewpoint.
Google's Kubernetes project has also straddled this paradox in the cloud, attempting to avoid some of the contradictions of static hierarchical imposition, but for imposed applications. The Internet of Things is just like the cloud, but where the applications are more emergent than imposed. We are ultimately constrained from the bottom-up, so top-down solutions cannot help.
One could build something like workspaces with Kubernetes-like cluster manager, where each agent promised its own firewall autonomously no matter where its geographical location. When I proposed this to Kubernetes developers there was little interest at the time, but this must change in the future.
As we really scale systems, e.g. in the IoT age to come, locality will play a larger role. The idea of aggregating all data and control into a monolithic cloud platform, even as we break up the software into microservices is a curious paradox of developers. It shows that we all tend to make monoliths out of the things we understand least.
Kubernetes is still probably the closest thing we have today to an adaptive cognitive control system for complex workloads, but there is great potential for unikernel technologies, like IncludeOS.
If we accept that everything benefits from maximizing the autonomy of low level pieces, like microservices, in order to make a larger surface area, then we need to manage that surface area by promising clearly how porous that boundary is. Everything from IoT to cloud becomes an issue of managing workspaces that intersect with responsible human system owners and clients.
Seeing inside the trusted black boxes (Istio and beyond)
Docker containers have become a de facto standard for deployment, which emphasizes opacity and shrink-wrapping. So-called `serverless' or `function as a service' wrapped software is also on the rise. We are in a race to turn up the level of plastic wrapping on our software, increasing its runtime overhead, to reduce cognitive overhead for developers.
People even chide: "if you need to see inside, you're doing it wrong!". Personally, I tend to think that people's needs are their own business, and that complex organisms need surgery from time to time. Even if we design `statelessness' into containers, so that they can be pushed out as updates, there is realtime state information inside these containers that may be more strongly coupled than developers realize or care to admit. Moreover, Linux containers are not truly isolated the way a unikernel can be.
So, which came first, invariance or trust? When you can't trust what is going on in some machinery, because its behaviour is not invariant as promised, you want to open up the hood or bonnet of your engine and take a look at how it works. When computers were big and slow, we could still do that. Now we need to transduce information to an amount and timescale that matches our human cognition.
System designers prefer a surgical approach to repairing systems (repair and redeploy). Operators may prefer a more pharmaceutical approach (like CFEngine - swallow and maintain state).

Offloading details is key to scaling with trust, but the need to do an X-ray remains: we just can't retain and channel all the information from inside a boundary to the outside, at all times, without consequences to that coupling. This is why biological immune systems scale the monitoring and repair by distributing it across multiple scales. Exterior scanning, tomography, X-ray etc of every person at all times is the obsessive compulsive (OCD), trust-free approach to system comprehension.
Commoditization branding is about managing this paradox---a deliberate scaling strategy for compressing information. We trust commodities, i.e. indistinguishable, uncontroversial symbolic things that keep clear promises and have no particular distinguishing moles or features. This is why we think in simple low information brands, logos, and sports teams. We stop analysing and we trust with an extremely low information cost.
The alternative to trusting is to build that expensive tomographic relationship to the machine on the inside --- to learn to "know it like a friend", from every perspective. Knowledge is based on relationships, on repeated experience. It is a cognitive process. It is expensive, as Dunbar's limit emphasizes.
This scaling issue is now hounding us in technology, as we work on larger scale systems combined with multifarious purposes overlapping concerns (heating and lighting can't be completely separated, traffic and buses overlap, etc). The business demands of widespread technology use are increasing speed and with relentless pluralism. Human cognition is now a limiting factor, and microservices are not the answer to it, because they exist at a scale that is a out the backend, disconnected from the source of the complexity.
With a group at IBM Watson, I've been working to apply a kind of machine learning to this problem of throwing away information efficiently, and leaving it to `artificial intelligence' to build a relationship on demand. We are studying cognitive learning processes to filter out contextual noise and identify invariant promises and patterns of behaviour.
Probing microservices and other containerized clusters - Istio
There is a lot of technology being built today to address modular deployment. All of its wrestles with the dilemmas of interior versus exterior. Where to draw boundaries, what information to keep and what to throw away.
The ability to explode schematics and get inside the workings of an industrial process is compelling, like ripping the paper off gifts, and it is one of the chief selling points for microservices and so-called serverless models. Platforms like Kubernetes and OpenWhisk are steps in the evolutionary ladder towards a redefinition of consolidated but open resource sharing.
Container based approaches, including serverless functions as a service, add extra wrapping and extra cost to the operational promises of IT systems. They are inefficient from a resource perspective, but they offload the responsibility for this efficiency to a specialized service and therefore push costs onto someone else. The exception is the Unikernel approach which is a bottom-up solution.
Recently, I've been working with IBM at Watson labs to address the cognitive challenges of scaling in a way that can be built into these platforms. Everyone knows Kubernetes now, and its cluster management of containers. Newer and complementary is Istio, which adds back observability by peering inside container boundaries with sidecars, and restoring the cognitive information channel for insight and debugging. The point of Istio is to let to form a new relationship with the inner workings of an introverted system. This gives a kind of tomography for peering into Docker workloads.

Using layer 7 creatively, Istio can route and inject faults into API calls, breaking promises selectively inside containerized workloads. So we can imagine training an artificial reasoning system to understand different anomalous occurrences, following data over long times, in a way that humans simply cannot grok, due to the Dunbar limits. We can then feed the telemetry into a machine learning platform Cellibrium that I wrote years ago. This combination would actually be a nice contender to implement workspaces when IoT starts to take off.
The two aspects of systems: "watch and learn versus decide and promise" somehow reflect the concerns of Dev and Ops:

Build your system, automatically instrument them by capturing generic invariants, then zoom out and see if there is still any separation of concerns. Identify symbolic states, and employ interferometry to detect causal changes: the re-emergence of micro monolithic behaviours.
The importance of forgetting state
The essence of hierarchical scaling in organizations is the need to divest oneself of the responsibility for maintaining a relationship with every detail. The low cost of storage today tempts us into the illusion that we can create meaning from `big data'. I believe that flatter workspaces, with weaker coupling (greater autonomy), are a better answer to the problem. To make this work, we have to eject certain ambitions to know everything. We have to trust more and verify less. To make that easier, we need to understand systems better on a theoretical level. The age of push it and see is coming to an end.
There are 2 reasons for deliberately forgetting information:
- Information loses its contextual meaning, as time goes by, so only invariants are worth keeping.
- New signal gets overwhelmed as a drop in the growing ocean, because forensic searches are not cheap.
Context might grow like O(t2), and history like O(t). Even if we could store and retrieve the data, in a timely fashion, the moment has passed. Evolution has allowed us to forget for a good reason. Every time we aggregate resources to achieve cost saving economies of scale, we lose causal information about the system. This is why we modularize by function as much as possible.
Our project at IBM, Istio with Cellibrium, to automate the extraction of contextual invariants is designed to optimize forgetting.
Mixing it up for innovation---modules will eventually kill a system
Innovation is the capacity of a system to generate new promises and states that were not previously available to it. Sometimes that is useful, other times we call it bugs.
First we mix it up and exploit network diversity, then we create a tightly coupled monolith to build a new agent, with new promises. Mixing, or recombination of basic elements, is the what leads to innovation. This is why the chemistry of cooperation, as undertaken by promise theory, is important. A future of purely rigid modular isolation is a future of semantic stagnation, and of only quantitative growth. If it weren't for the fact that ideas and commodities perish and fizzle out on human social changes, economists would be happy to simply grow in quantity like a cancer in biology. But if humans also stop changing, because our requisite diversity is saturated by automated goods and services, then it's really the end the human age, as argued by Joseph Tainter.
Some have argued that this will lead to the end of work, but I'm betting that ordinary people will be smarter than than, if they can avoid the mass mind control that massive scale can wield on our field of arrows.
(V) The Scaling of a Smart Society
Someone invented the pejorative `code monolith' to ridicule a scaling argument that failed to account for an end-to-end system. But what does this mean for us on a larger scale than just IT? Cities may well show us the future of code, and lead us to see the future of society as one in which every cubic centimeter of space is functionally relevant, as a seamless informationscape.

The purpose of a monolith is to be singular, simple, and invariant: to function as an easily remembered symbol, to convey invariant meaning.
Ultimately the abstractions we use in society are cultural, not technical. Forgetting about detail is something we need to embrace, not disdain. Keeping evidence for forensic inspection must have a short finite lifetime, else we will lose the ability to distinguish signal from noise. Or we will have to apply cognitive assistance, perhaps using an immunological scaling approach, to pre-empt trouble. Finiteness is not just a limitation but a survival strategy. Symbols are monolithic in information theory because they are semantic primitives. How we choose our semantic primitives is a design question---one of language.
Money
One of the first global shared network technologies was money. Until recently money had no memory. It has been a high entropy commodity, composed of many indistinguishable parts, common and therefore easily to trust. Cash forgets what it did instantly. What makes money easy to pass along is its low information simplicity. If money could remember where it had been and who had used it for what, we would be much more careful about trusting it. We might not want to handle money that enemies had touched, or attach special value to money that celebrities had used.
Today, electronic money can remember these things, but with a growing cost for every transaction that slows down exchange for obsessive traceability. This make people willing to use cash, as no one wants to be scrutinized to in infinite detail. Now BitCoin and blockchain could keep the entire financial history of the universe on slower and slower money, but there is a simple reason why this will not happen. Trust and scale.
The trusted third parties are banks (you might not trust them as much as you need to). This is unsustainable. As we modularize money into microcurrencies (flight miles, coffee cards, smart contracts attached to digital media, etc), we'll achieve autonomy, and the ability to reprice goods and services flexibly, with even greater semantics. Those may prevent us from exchanging one microcurrency for another. The requisite diversity for sustainability could be compromised by having too much information. Modules intentionally break the flow, and we will have to manage multiple currencies instead of one. But our brains are not getting any bigger, so there will be a limit to what we will accept of this. The Dunbar limits tell us that we can't support too many of these. Our forbearance of too much/too little information tends to swing like a pendulum between extremes.
Debt exists essentially to maintain trust. Modular boundaries insulate us from cultural practices that we prefer not to see.
Semantic spacetime---the separation of scales as well as concerns
Innovation is also a cognitive two part process: extrovert mixing (or exposing an agent to noise), and introvert gestation (by isolating from further noise while seeking a new invariant outcome). Evolution repeats and selects the successful mixtures from the unsuccessful ones.
When we develop technologies or innovate, there are always versions that separate long times from short. Experimental development is always monolithic and built as an appendage that sticks out like a sore thumb, as an extension of ourselves. We always insert ourselves into the problem initially. When we finally figure out how to scale a problem industrially as a commodity or a utility, we end up distributing it so that space itself promises the result. I call this semantic spacetime. Cognitive assessment, manufacturing, and maintenance are cheap, when information can be compressed and mass replicated.

The image above shows humans inserting themselves into the picture, then building cyborg services to try to scale that, before finally writing themselves out of the picture by programming space itself to deliver the necessary services.

This image shows another example of people inserting themselves through monolithic systems, attempting detailed balance with a singular vertical scaling strategy, ignoring the scales of the problem. Then finally by programming space itself to scale the functionality humans can write themselves out of the picture.
Summary
Modules and boundaries do not exist in a vacuum. The way we choose modules may lock us into a particular conceptual perspective from which it is hard to escape. Adaptation is a cognitive process, and we are still struggling to adapt our rigid technologies to this challenge.
Even in this story, you can see that. While I tried to make a modular story, there is a chain of narrative dependency that makes the story worth while. Our concept of logical reasoning is really just a form of story telling. If we can't tell simple stories about systems, we won't understand them or trust them. This is a challenge I am trying to address, along with some of the teams at IBM Watson. Istio mirrors our current set of concepts around Docker containers. It will be interesting to see what the next chapter might be.
Which came first, invariance or trust? Boundaries help us an hinder us in managing networks dynamical and semantic resources that space and time offer us in an increasing variety of forms. Does the need to seek out bilateral promises (rather than unilateral impositions) lead to a better system? Is a bossy dictator better than a free market? This surely depends on the level of coordination and resources needed, as well as the scale and the technologies we can muster to keep invariant promises.
What makes humans special in the universe (as networks) is our capacity to embrace innovation without losing our promise of who we are: our brains have evolved to tune in and out, to condense specific events into generic and invariant concepts, in order to cope with the onslaught of scale. Joseph Tainter observed that past civilizations have lived and perished by need to cope with scaling of cooperative functions. It remains to be seen whether our modern society can be as successful when wielding information technology. It could help us or hurt us. The breakup of a once uniform society into tribal microservices, thanks to the availability of detailed information online is happening before our very eyes, across the world.
We have never faced such a challenge of too much information before. The major question we need to ask ourselves is: should we be looking inwards or outwards, and with respect to what boundary?
