
Deconstructing the `CAP theorem' for CM and DevOps
Part 2: The greatest distributed system of them all
Is infrastructure just a database? The CAP conjecture, and the debate around it, talks about the trade-offs one has to make in distributed systems, between the ability to provide quick access to IT services and the ability to promise uniform behaviour from around the system, taking into account the unreliability of network communications. CAP is about the relativity of users and services in such an environment.
In the first part of this essay, I laid out these trade-offs in some detail. In this follow-up, I want to discuss what the three axes of C, A and P means for the largest distributed system we have: our IT infrastructure. I want to ask: what are the implications for continuous deployment, or DevOps in the world of data relativity?
[PART 1][PART 2]
Synopsis
|
Infrastructure as a ... database?
At first glance, everything is a database. The entire world around us is something that we read from and write to -- we use and we alter. Even if we restrict attention to IT infrastructure, our networks, PCs, and mobile devices, we are all living users of a massively distributed data system. From the point of view of CAP, this is abstract enough to be true, but how to draw insight from it?
The first requirement of an infrastructure is that it form a predictable platform to build on. Users have to know what they can expect. This means we need certain standards of conformity to be able to make use of the services that infrastructure provides. Infrastructure should also be ever present for the same reasons. This is two of the three CAP properties:
- Consistency - standards of expectation
- Availability - ready for use
One of the questions I shall try to shed light on here is to what extent these general formulations of C and A need to be matched with low level transactional data properties discussed in part 1.
For the third property P, we need to talk about all possible system partitions, not just client server interruptions. For infrastructure, data partitions can occur at many levels. Infrastructure does not have the simplicity of a single client server relationship. It has structures within structures, encompassing a variety of needs revolving around resource management. Some partitions are intended: access controls, firewalls, user accounts, running processes etc. Some are born of unreliability: faults, outages, crashes, etc. How infrastructure continues to serve users, while dealing with each of these gives us P: partition tolerance.
So clearly infrastructure too can be discussed in terms of the three axes of CAP, as long as we are careful not to think too literally. By working through these ideas, in this essay, I hope we can learn some things about infrastructure from databases and vice verse.
Infrastructure's nested containers actively partition data on purpose. Process caches challenge consistency by blurring the lines between system and application i.e. server and client. Availability can be promised and withheld over a variety of channels: a kernel switch, an internal bus, the Internet, a VPN, etc.
Finally, infrastructure components look less like static archives than many databases do; they are dynamical, with some data (e.g. monitoring stats) actually changing in "real time", relating to the world around. There is a continual dialogue between the world and IT infrastructure and applications that we hope to shape and manage. In part 1 of this essay, I pointed out that the idea of consistency in the CAP sense needs to be re-examined when we consider the end-users as being part of the data system too. These are the things we shall be considering.
Example: DNS. A familiar, if not beloved, example from the Internet:
- Consistency (C): When an address-name mapping is looked up by anyone, anywhere in the world, we would like the information to be unique, up to date and uniformly consistent. Of course, this is far from true. Programs can cache values, hosts can choose their own lists of servers to query, availability can limit the accuracy of updates.
- Availability (A): In order to provide service availability, there are primary and secondary servers, caching daemons, and encoded TTLs (Time To Live caching policies). When a change is made in DNS, we expect to have to wait for TTL seconds (often several hours) before everything will be all right -- and we typically plan for this and work around it. When do we start counting this TTL? That depends on when we last queried the provider of the TTL, and anyway this is advisory not mandatory, so it is really up to individual systems to decide. There is no nanosecond predictability here.
- Partition tolerance (P): user processes might cache their own results, within their own private world. A change in DNS cannot affect this. DNS does not work through automatically through firewalls, or in virtual machines but a particular server is only temporarily unavailable, BIND will try up to three servers from a list in order to resolve an address query. Local caching can guarantee an answer to a DNS request, depending on configuration, ensuring something like availability or even partition tolerance, but in promise-theory terms, the DNS server-side itself cannot make such a promise, only the DNS client.
Some questions pop up. Lines are blurred. Clearly the concepts of CAP are somewhat simplistic in a real system.
Which partitions do we consider to be part of the CAP system, and which are considered to be external, i.e. the responsibility of end-users? Also, what timescales do we set for ourselves? How long is permanent, and temporary?
DNS works pretty well most of the time, in spite of a plethora of system partitions to deal with. Like other network services (BGP, for instance) we expect its data to be slowly varying on the timescale of other processes that are using its services, so that caching becomes a winning strategy. As infrastructure, that makes it relatively predictable, even if its status as consistent, in the CAP sense, is questionable.
Honey, our atoms are getting bigger
The classical approach to maintaining consistency in databases and filesystems is to arrange for a protocol that ensures "all or nothing" transactions (serialized copy-on-write, etc). The idea is that, if a database never gets out of synch' in the first place (on a first come first served basis) then it can never become inconsistent, as we then control the every detail of the data store's interaction with the environment. In this way, equilibration of a database (see part 1) is a quite inexpensive process. In low level data systems where the outside world can be effectively excluded, this is a plausible concept.
At the level of infrastructure services (hosts, network services, web services, applications, etc) this approach simply cannot apply. infrastructure services are by their very definition not isolated from the outside environment with serialized interactions, they are highly parallelized systems that interact with users and receive signals from networks, keyboards, and a variety of other sources in a completely uncoordinated way. One of the main causes of configuration drift on computers is human intervention. If a human being logs onto a computer and makes a change, in what sense is this consistent with all of the other 1999 computers in a cluster?
System administrators have tended to measure consistency of services by a different standard than, for example, databases. One does not look for data consistency, but rather approximately correct behaviour. In practice, the long standing approach of many organizations is to wait until someone complains about something, or to set up some form of monitoring. I'll come back to these issues below.
The key to maintaining write consistency is to define atoms that change entirely in a single transaction. In databases these are key-value pairs, i.e. the smallest objects that can change independently on the system. Each key value pair transaction is locked so that one knows exactly what goes in and comes out. In CAP, this is the CP without A trade-off (see part 1). In software and infrastructure management we think in much larger terms however.
The units of change in which developers and system administrators/operators tend to think have been getting gradually larger and more open over the years as the scale of IT systems has grown and technologies have tried to keep pace.
- Configuration files: in the halcyon days of Unix prior to the web, wizard-like system administrators could easily write scripts or even manually change essential details about systems to configure them optimally and repair problems. Unix was designed to be easily configurable with flexible tools. Configuration was always available (A) to the superuser in Unix-by-hand, and there was single-user-mode to shut off disturbing factors (P), giving a kind of transactional status to manual labour (C). So this was a CA without P regime for a very simple monolithic architecture.
- Software packages
During the 1990s software packages were introduced to some Unix
variants, allowing software to be selected or rejected depending on
need. In the early 1990s computers were installed from tape drives
with a standard version of the operating system and no
configuration. It was not build process in the sense of today, but
more like a studio woodwork project, poring over printed manuals
delivered as dozens of ring-binders. Operating system installation was
all or nothing, but this would not deliver a working system. Then it
had to be finished. Package managers made this gradually easier.
Thus the atoms of installation were changed from an entire operating system
to software packages. The packages could not be changed independently
then, there were no upgrades, and patches were usually manual tarballs
that wrote various files, independently of the package concept.
With the advent of GNU/Linux, packages became more sophisticated and started to include partially finished configuration files too. There were versions and patches also that could be applied per package now. This was a blessing and a curse, for now there were two independent sources managing configuration data: you and the operating system provider, fighting for dominance. When a package update came along it would typically overwrite your configuration changes because the size of the atoms was too large. This was a lack of consistency due to a mismatch of models, but it could happen in multi-user mode: an AP without C regime.CFEngine was an effective antidote to the package manager problem, as it allowed system administrators to set policy for details within individual files, as well as changes at the package and process level, and this would be continuously maintained, not merely installed once and abandoned, thus when security patches to Apache installed over configuration files bringing down a website, CFEngine could have it up again in 5 minutes without human intervention.
CFEngine turned "AP without C" into "AP with C in a few minutes". So there was a window of possible inconsistency that would be equilibrated. Also it scaled to all hosts because all changes were made on the end-user hosts, in a decentralized fashion. This is Shannon error correction.CODA: later package manager versions would not overwrite changes that had been made locally, or fail to update the files or even the whole package. This still causes problems today.
- Hosts: Golden images The arrival of Windows as an all or nothing operating system at a large scale, but without any speakable management tools, put system administrators on the defensive. It led to the era of blasting machines with an entire pre-configured image. Everything had to be the same. The lack of distinct user IDs in early Windows meant that each new user could corrupt that image. Some institutions would re-image machines regularly to counteract this data corruption. This, like the CFEngine case above, is basically Shannon error correction over a much longer timescale.
- Virtual hosts Today, all of our progress has brought us back to golden images due to the pressures of scale. Cloud technologies have made it easy and quick to build machines from golden images through Infrastructure as a Service. That coupled with the explosion of scale and lagging quantity of operations experience has put system administrators back on the defensive. Better to replace a whole machine than figure out the error at a lower level. If you don't have the tools, this is the least expensive option.
- Clusters Organizations that perform specialized computations run "compute-clusters" where every host needs to be identical to be able to put tight limits of Service Level Agreements for completing jobs. Variations in hosts can affect jobs in different ways, so data consistency of the operating system and software is required for a duration of each job. Clusters are expensive and need to be highly available to make money. They therefore have to have database like consistency and they are totally dependent on network communications: this a CA without P regime.
- Data-centers Clusters are very monolithic, but datacentres (or virtual datacentres) typically represent more differentiated or tiered services. Common today are web shops, of course, with databases back-ends, web-servers of different kinds, and application engines. Tiered applications, differentiated services, versioning of software are all issues here. Complete uniformity is not desirable, rather we see computers playing different roles. With advances in configuration management and building of systems, it is possible today to perform "version branching" on a whole datacentre by replicating, altering and migrating all new users to the new version, then deprecating the old. Thus there is an atomicity to the change, but migration takes a finite time as old users complete tasks and are moved to the new infrastructure. This is also a CA without P regime.
We can add one more item to the list above, namely "cookbooks" (in Opscode Chef terminology) or "design sketches" (in CFEngine terminology). These are bundles of configuration atoms at the level of files, processes and sometimes software packages too, that simplify the interface, encapsulating various related elements under a common flag. So we can say "tomcat service" as an atom, and that sets up everything related to the software, its configuration and its dependencies, like a database on the back end etc.
At the heart of these steps is the question about a choice: what do we want from consistency? Should systems really be all the same? Is that really what we want? (See my discussion about the rise of personal freedom as a force in IT, What drives technology and CFEngine, SysAdmin 3.0 and the Third Wave of IT Engineering). I think consistency of infrastructure is another place where relativity plays a role, for now we have not only relativity of location, but also of intent.
In practice, it seems that CA without P is the only option in use. But this is a slightly misleading view, as in operations we effectively use partitioning as a tool to arrange for each user to have this experience within their own private partition, much as advocated by [11]. Moreover, it assumes that we never make any changes or repairs (which is a CP without A regime). The point about atom size is that we have to ask: how much of a system do we have to take down (make unavailable) to make a fully location-time uniform repair, consistent over all frames of reference?
At the level of infrastructure there is no boolean right and wrong, only policy that covers multiple atoms to determine a level of correctness according to intended state.
| By making atoms bigger, we can hide apparent inconsistencies. But we also hide potential conflicts and increase the destructiveness of the method. |
Separation of data into desired and actual state
In the science of dynamical systems, there is a method that has been reinvented many times and goes by a variety of names. Let's call it the adiabatic approximation. It is about splitting the changes going on in a system into fast and slow components, like ripples within waves.
The slow changes represent long term trends of the system. The fast changes fluctuate against this backdrop of predictability like noise. What one calls long term and short term is highly context specific, of course. For an excited atom, long term might be a nanosecond, for a computer system it might be a week. Fast and slow change: fluctuation and trend, noise and signal. Slow changes are what the fast changes can rely on to be more or less constant because at their timescale they don't notice the slow changes -- the ripple does not notice the gentle curve of the wave it lives on.
This kind if separation into fast and slow is a property of weakly coupled systems, or systems without strong couplings/dependencies. Such systems tend to stabilize and fall into long term patterns. If you cannot separate your system into these parts, because it is so tightly coupled, then you have no long term predictability. Such systems are called chaotic in physics. Systems remain stable because of a process of equilibrium for the fluctuations. If fluctuations are countered or repaired at the same rate that they occur, we can maintain the quasi-stability of slowly varying trends. If fluctuations are allowed to grow, they will eventually reach a limit of instability.
In computing, evolutionary experience generally drives us towards weakly coupled systems, from bitter experience, and we govern change in our systems to match the two timescales: policy determines how the slow variations or trends will be shaped, while continuous repairs determine short term state. Actually not many organizations make continuous repairs, and so their systems eventually drift off in some direction away from a stable state.
Shannon error correction (CP without A)
In digital systems, Claude Shannon pointed out how this applies to digital integrity, and essentially predicted the mechanism by which all memory systems perform automated error correction today. Because binary digits are constantly being attacked by cosmic rays and electrical noise, data integrity has to be actively maintained by algorithms we no longer think about, repairing bit-errors as fast as they occur.
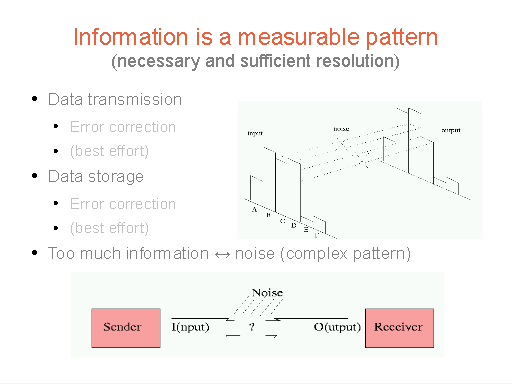
As a system evolves into the future, it picks up noise
every step of the way, just like any other message transmitted
on an open channel.
| In 2000, I showed that Shannon's theorem (a real theorem) could be applied to infrastructure with a bit of work and turned into what I called the Maintenance Theorem. This was the work on which CFEngine's regular 5 minute maintenance regime was based. The time scale of change was originally hours by human intervention, but with the rise of the network it has become minutes. |
Shannon error correction is simply about taking atoms (which he called alphabetic symbols) and detecting the deviation by probabilistic best-effort means, and rewriting corrupt atoms correctly. This is done on a bit by bit basis in storage and signalling. For infrastructure, we would apply it like this:
- Configuration files. Re-edit lines or values in files/processes (CFEngine)
- Processes. Overwrite relevant files/processes (templating engines)
- Packages. Overwrite package (RH satellite, bladelogic, etc)
- Host. destroy and rebuild host (cloud/VM infrastructure)
- Datacentre. Rebuild datacentre.
| What the CAP tells us about repair is what is codified into promise theory principles, namely that we should make changes at the smallest most atomic scale to minimize their impact on users. This, of course, is a basic mutual exclusion principle for in locking shared resources mutex. Making minimal touch change also increases the rate to probable equilibrium. |
Obviously the more blunt your instrument, the bigger the impact of this change. Since this is a CP without A regime. While we are making a destructive change, the system cannot be available for normal use.
| As a coda to this section, I would like to note that the old approaches to error correction have struggled to keep pace with the scaling up of infrastructure. The probability calculations on which errors were computed have been invalidated by modern scales: even a small probability of error becomes a large amount of data when you scale by several orders of magnitude. The days when we could believe in simplistic notions like right/wrong, true/false are fading. Today it is all about the probabilities. So far they have not affected us too badly. |
Entropy and the consistency of information
People often ask me about the concept of entropy and how it relates to CAP and configuration management. Entropy is a subtle technical concept that has entered the public consciousness in two areas: in the sense of general disorder (through the second law of thermodynamics), and in cryptography as a measure of password quality. These are both interpretations of entropy.
| I wrote at length about entropy in 2001, in a popular series for USENIX called Needles in the Craystack. |
Entropy is actually a measure of distribution or sameness. Imagine a histogram (bar chart) that counts things in different categories. Claude Shannon, one of the main inventors of modern information theory, would refer to all these categories as an alphabet, as he was concerned with sending coded digital messages, but such categories can represent anything in our minds of course.

Shannon defined entropy to be a measure of how uniform, or spread-out the distribution is, and this was later shown how to agree with earlier definitions from thermodynamics, underlining the deep connection between equilibrium and information. The extreme cases are clearly, minimum entropy in which there is only one category that everything falls into.

So in physics we say that a system is ordered, or low entropy if all countable occurrences of something are tidily composed of only one flavour of state, or perhaps just a few. The more different cases, flavours or alphabetic categories we find, the higher the entropy. So, then there is maximum entropy, where everything is divided equally to fill the maximal number of different categories.

This is the interpretation of entropy in the sense of passwords. A high entropy password is one that uses the maximum possible range of symbols in the available alphabet, making it harder to guess in the sense that an attacker has a equal probability of finding any character for each letter of the password (increasing the number of possible guesses by factorial levels for each character).
How to use the entropy concept for infrastructure consistency. To talk about entropy, we should ask: in what sense is a state spread out like these examples above? Well, in a distributed system there are three ways (three dimensions) to talk about distribution of state.
- Distribution of all equivalent key values data different possible
values (the alphabet = list of alternative configurations).
e.g. Unix file permissions on /etc/passwd, counted over all our hosts, with possible states: A = 664, B=755, C= 600, D=777, etc).
Because this is about wanting order or consistency (C) we want this to be low entropy - just one actual state value everywhere. - Distribution of the occurrence of a data value in space (alphabet = computer/host).
e.g. count Unix file permissions that are exactly 644 on /etc/passwd, counted over many hosts: A = host 1, B = host 2, C = host 3, etc.
Because this is about policy compliance, we would like the distribution of this desired state to have maximum entropy, i.e. be spread equally at all locations. This is what we called equilibration in part 1. - Distribution of a data value over time (alphabet = time of day), which we would probably intend to be uniform also, unless there were some intended reason to change the permissions in order to make the password file unavailable.
The entropy of a policy modelled state is thus related to how uniform or consistent (C) the observed data occurrences of that state are. So, suppose we think of a system policy as taking the values in the alphabet of case 1 above. Equilibration of policy consistency (C) is about spreading this uniformly over all hosts and times, as in cases 2 and 3. So what does CAP say about this?
Well, because the policy model for infrastructure changes only very slowly compared to the usage of the system, caching is an effective policy for availability of the policy at every host node in a network. Thus, as long as policy does not change, we can have 100% availability (A) of policy by caching it everywhere (equilibrating) for weeks at a time. If we copy the policy or arrange for it to have a separate source in every intended partition, like firewalled areas etc, the we can have 100% availability in all of these too. Moreover, since network failures are fluctuations that happen quickly (minutes) compared to the rate at which policy changes (days), we do indeed have fault tolerance in the sense of policy compliance and it is completely implementable at every location in the distributed infrastructure, allowing 100% consistency to within the time-accuracy of the fluctuation repair schedule.
Thus, because this makes the distributed infrastructure into a system of "many worlds", each with its own autonomous consistency, we are not limited to achieving only 2 out of 3 of the properties of CAP, we can have all three as long as the policy doesn't change, to within the engineering tolerances of the configuration system (e.g. CFEngine repair every 5 minutes).
| The time scales and the relativity of autonomous configuration management are thus such that, for all reasonable definitions of consistency, availability and partition tolerance, we can have 3 out of 3 CAP properties at the same time. |
The local rate of repair is thus now the main limitation on the policy compliance or consistency of the distributed system.
Finite rate of repair: MTBF and MTTR
In part 1 of this essay, I underlined the importance of time and separation (space) to the question of uniform consistency, in other words: relativity. There the issue of potential inconsistency was the finite rate at which information can be transmitted. Let's return to time relativity and see what it means for infrastructure.
Errors and faults are often talked about in terms of a classic two-state model in which systems are either broken (i.e. there has been a failure) and repaired. In this two state model, we are always either waiting for a failure (working) or waiting for a repair (broken). The Mean Time Before Failure (MTBF) is the average time we might expect to elapse between failures, and the Mean Time To Repair (MTTR) is the average time to return it to a working state. (These designations vary slightly in the literature.) Like all states (whether low level data values or composite states like "broken") these persist for finite intervals of time, and the system flips between the two, always in either one or the other.
In the sense of configuration management, the correctness of data is what controls correctness of behaviour and whether there are faults or not at the software level. So repairing data is repairing the system. This model therefore assumes that when the system is broken and being repaired it is unavailable. Five nines etc.. So it is a CP without A regime. But how much of the system do we have to take down when there is a failure?
The answer to that question depends on the atomicity of the configuration system. If you can only replace a whole image, then you have to destroy an entire machine for the time it takes to do that. If you can only replace a package, you have to affect an entire (possibly live) application for the time it takes to do that. If you can change just a single file or some bits, then it takes only a moment.
| My standard irony: how many sysadmins does it take to change a light bulb? Many, because you have to tear down the building and re-image a new building that contains a working light bulb. |
The MTTR is shorter if a repair system can touch the smallest components easily.
How much could you lose in a second, in a minute?
If we want to maintain infrastructure consistency with a model of system policy, we have to counteract fluctuations that break the system for MTTR seconds long. That means to prevent fluctuations (noise) from growing out of control, we certainly need MTTR ≤ MTBF. An example of this is garbage collection. Some of the fluctuations might cause large deviations, but they will be corrected within the time (e.g. for CFEngine the default would be five minutes).
To avoid any effect on the major trends of behaviour, we need to be quicker than that: we need the repair time to be much less than the time between failures (MTTR << MTBF) so that, fluctuations of state consistency cannot grow large enough to make an irreversible impact, because of the rate of growth in the flutuations is very high (and you have a slow configuration management system) the fluctuations can still win and bring about potentially irreversible configuration drift.
Now relativity of distance comes back to haunt us. If systems are managed remotely, then latencies add to the MTTR and are prone to further modes of failure by communication loss or partitioning (P). This makes the certainty that hosts will be in a policy consistent state less. In other words, you want the management of infrastructure to happen from as close to the point of application as possible (at CFEngine, where there is an agent on every independent host, the motto is "configuration management from within"). Network shells and other remote control web consoles where the instructions are sent over the wire from a central controller are inherently inferior due to this relativity.
The truth of regular maintenance is that most fluctuations do not become failures if handled quickly enough. e.g. if that log file does fill up the disk, the system would not freeze.
| Parallelism can be the friend as well as the enemy of consistency. If you force repair to be sequential, or "imperative", making a chain of dependent strong-coupled steps, the MTTR has be to longer and a failure to repair will prevent other repairs from happening. If you can parallelize repairs and make the steps as independent as possible, then the MTTR can be maximized. |
Push versus pull
In several places throughout this essay, I have suggested that push based systems are uncertain. The UDP protocol is called unreliable for precisely this reason. Let's summarize the consequences for infrastructure.
I have any number of design objections to push based systems, including network shells and package pushers that indiscriminately amplify human error around a network without any critical evaluation (pull systems can also amplify human error, but they make it easier to put layers of due-diligence in between the intent of a pushy human and the trusting recipient). Trespassing across the boundary of another agent without regard for its current condition or wishes is more or less the definition of an attack, so pushing changes to infrastructure is similarly indistinguishable from an attack on that infrastructure. But let's not get sidetracked from the CAP story.
The main CAP weakness of a push based approach to change is that there is no feedback loop capable of monitoring whether a change succeeded and how fast the information travelled, so we cannot define the availability of that source, because there is no concept of a time interval, just a point at which you "throw something over the wall". If you don't know whether something is available, then you also can't know about consistency. Indeed, a push based mechanism for updating s distributed system has no method of knowing if a remote write succeeded. Actually all write operations and queries might be considered pushes at some level, but that is not the sense in which I mean push here. A disk device is listening autonomously for writes, and services them with low level atomic verifications about the success of the changes. It is not the same as doing a UDP push to syslog, pushing a MIB over SNMP, or an rdist to a remote host, where there is no real validation.
Some people still try to think deterministically: if I push the button I am in control. But this is not true, because the changes cannot be made transactional or atomic by push -- as you have no idea who else might be pushing something from somewhere else. It is precisely the distributed inconsistency of this notion of remote obligation of systems that led to the first presentation of promise theory in An Approach to Understanding Policy Based on Autonomy and Voluntary Cooperation.
The old fashioned approach, that worked `okay' back before the mid 1990s, when there were just a few machines in an organization, and there was usually a single system administrator in charge of everything, was to set up some kind of monitoring system to verify the eventual state. The common monitoring of its day was transported by SNMP, which was itself a push protocol. So let's finish this essay with some remarks about monitoring.
Monitoring and timescales
What would a monitoring system be able to tell us about system consistency? And would we want it to tell us?
Earlier I explained that we can only define consistency as fast as information can travel between observer and data and back again, due to the relativity of knowledge. This suggests that monitoring of data is also fundamentally limited by the same issues discussed by CAP. So let's examine that.
There are plenty of reasons for monitoring systems, some psychological, some informational. Typically, we want to see what we believe to be consistent information about a distributed system in the hope that it will be bring us certainty about the state of the system. But is this even possible? Let's start by comparing this for a database and for infrastructure.
- Databases arrange for certainty through atomic transactions that, to a high degree of probability, guarantee consistency. Checking data consistency is of limited value in a database as the data could be changing much faster than we would be able to follow. At best one could measure the effective latency -- which would be an admission of the fundamental relativity of data simultaneity.
- Infrastructure, on the other hand, cannot ensure transactional integrity at the outset, because infrastructure change is a process that happens on too large a scale, by too many parallel processes. Different processes divide up the into different and inconsistent atoms: files, packages, applications, processes, etc. Those atoms are too large, and timescales that are inconsistent so that change data in parallel and without any single transaction monitor (except the system kernel) to watch over them. We often do set up monitoring of certain pieces of this puzzle, because some of the changes are quite slow and can be seen with the naked eye.
In the first case, we are happy to trust the integrity of the system to a gatekeeper. In the second case, there is no gatekeeper. And as usual, the consistency under change is all about the timescales.
Configuration management convergence. In a policy based scheme of change, where we can define signal and noise, policy and fluctuations, configuration management can take care of probable consistency, in a way analogous to what happens in a transaction monitor but over much longer timescales.
The difference between infrastructure and a database is that, once a value has been written, you cannot be sure that it will stay the same in everyone's view. The effects of relativity are amplified by the openness of the system. The notion of convergence was introduced by CFEngine in the 1990s to maintain integrity to policy or desired state because it could be changed by uncontrollable sources at any time. It then becomes "a duel", in the game theory jargon, or a race to maintain control over the data by checking it continuously. It is like having a gardener pull weeds from flower beds on a continuous basis. If he is not fast enough, the flowers will be overrun by weeds.
Analogous to databases, configuration management can arrange for a proper state to be written in the beginning, with some transactional control -- but unlike databases, more like gardening, it will start to decay immediately. So we have to add back maintenance by promising stochastically probable consistency by repeated micro-verification, over an acceptable timescale. We are in a race.
Just like a database, the automation can do this without a human needing to be involved, as long as there is a model of what is correct, or desired state. Then, if we have identified an inconsistency in a system, would it not be better to go the extra mile and simply equilibrate the system to remove the "delta" without needing to wake up humans on their pager? Indeed, waking up humans allows them to worry, but it doesn't necessarily help fix the problem.
| With a local, many-worlds repair system like CFEngine or Puppet, that needs no centralized contact needed with a controller (so without a Puppetmaster which creates a remote dependency), you can literally have faster-than-the-speed-of-information consistency. Consistency teleportation, if you like. You can believe in it, because there are guarantees, but you just can't verify it faster than that. As soon as we tether something to a server, or make a distributed dependence, that will limit the speed of data consistency. This is why we separate policy from implementation in the first place. |
From a CAP perspective, classical monitoring systems make very little sense. Monitoring systems do not generally make clear promises. They don't tell you how much latency was involved in the collection of the data, whether you are seeing something that happened a millisecond or an hour ago. SNMP cannot, in fact, report this information without assuming the existence of globally consistent time, as it is a push system. Two uncertain things does not make something more certain, it makes it less so.
How would we expect to measure a system's consistency with a tool that cannot even measure its own consistency, and at a timescale that may or may not be able to capture the changes? The answer to this must depend on whether an inconsistency is identified as noise or whether it is a sign of an anomalous signal: that requires monitoring that understands the policy for the system state. Trying to solve this problem was what motivated the Model Oriented Monitoring in CFEngine. It is no surprise that CFEngine is at the heart of all of these innovations, because it was the result of research into these fundamental problems.
| If a host is unavailable (A,P) you just don't know what its state is (C), like Schodinger's cat. That does not mean the system is inconsistent. It just means that in your frame of reference, you don't have access to that information yet. If you've arranged for local continuous maintenance you are almost certain that it is. |
It is a question of trust or belief. How can we trust what we see? Do we need to see in order to trust? Does one thing help the other or not? I'll leave you with that question to ponder.
CAP and infrastructure
Continuous change is a feature of both databases and infrastructures. Uniform consistency of data is of more interest to database builders than to DevOps, where multiple versions and speed before certainty are acceptable risks to most people. The rate at which changes are made plays a large role in what we can expect to experience about a distributed system.
The CAP conjecture was about the consistency of data in "distributed systems" (with a strong prejudice towards database clusters), but it tried to describe trade-offs ignoring the key issue of time. In part 1, I discussed how time clarifies what the CAP letters C,A, and P can mean and can really tell us, using aspects of user-data relativity. In this second and final part I've discussed how these issues can and cannot be applied to issues at the scale of infrastructure, where the world is not really transactional in the sense of protected atomicity. There we can do no better than deal with probable consistency, because distributed systems are stochastic by nature.
In the 1980s and 1990s, database vendors came up with management models for infrastructure like the Management Information Base (MIB) for SNMP, and the Common Information Model (CIM), each with tens of thousands of relational tables to try to model infrastructure. The idea was that, if you can manage a database, you can manage infrastructure. Both of these models have been resounding failures, even though the technologies live on for tiny subsets of content in lieu of something better. My own work during the 1990s showed that infrastructure is not just a key value store, because dynamical systems are not mere data stores, any more than a human being is merely a skeleton with organs pinned to it.
Ultimately it's about trust, and mitigating uncertainty. Trust is really what CAP is trying to address, but its viewpoint is limited. Trust is a human issue. How much do I trust a system to meet my expectations? What kinds of promises can it make? Outside of distributed system engineering, we are used to putting up with all kinds of inconsistency. I constructed promise theory from the viewpoint of minimal assumptions for this reason.
A full and complete configuration management system allows users to document the IT all the processes as a single dynamical system in all of its aspects. Equilibration of human and computer systems, of business goals and low level data in a unified view.
Personally, I believe Computer Science is still working its way out of a naive view of determinism, and that infrastructure engineering is at the cutting edge of that journey. I hope this essay has offered something to think about as we make that journey together.
MB, Oslo, August 2012
Acknowledgment
I am grateful to John Allspaw, John Willis and Diego Zamboni for helpful remarks on a draft version of this article. They are, of course, absolved of any blame regarding the content. I would also like to thanks Ted Zlatanov for suggesting the topic.
Valuable reading on CAP theorem
- Eric Brewer, Towards Robust Distributed Systems?
- Eric Brewer, CAP Twelve Years Later: How the "Rules" Have Changed
- Nancy Lynch and Seth Gilbert, Brewer's conjecture and the feasibility of consistent, available, partition-tolerant web services, ACM SIGACT News, Volume 33 Issue 2 (2002), pg. 51-59.
- Daniel Abadi,Problems with CAP, and Yahoo?s little known NoSQL system
- Michael Stonebraker, Errors in Database Systems, Eventual Consistency, and the CAP Theorem
- Henry Robinson CAP Confusion: Problems with "partition tolerance"
- Coda Hale You Can't Sacrifice Partition Tolerance
- Nathan Marz, How to beat the CAP theorem
- NoCAP - Part II Availability and Partition tolerance
- Armando Fox and Eric Brewer, Harvest, Yield and Scalable Tolerant Systems (1999)
- Rich Hickey, Are we there yet? (2009)
- M. Burgess and J. Bergstra, A Foundational Theory of Promises (2004-)
- D. Aredo, M. Burgess and S. Hagen, A Promise Theory View on the Policies of Object Orientation and the Service Oriented Architecture (2005-2006)
- M. Burgess, Three myths holding system adminisration back...